Case Study: Map Reduce
Map Reduce Explained
MapReduce is a programming model for processing and generating big data sets with a parallel, distributed algorithm on a cluster. Let’s explain it here as a way to parallelize sandwich making.
Map reduce is a function that
- chunks the input,
- maps a function over the chunks in parallel, and
- reduces the results to a single value.
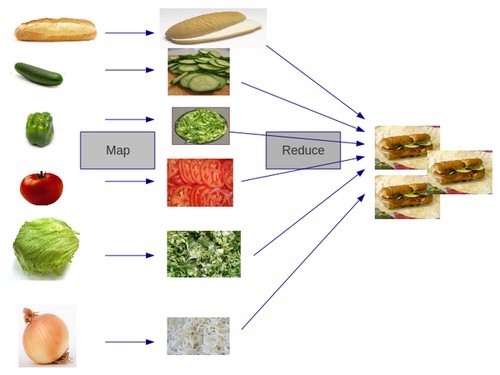
Map Reduce “Library” Functions:
The Haskell definitions of mapReduce functions, reflected:
Of course, for mapReduce to be efficient the map function should be parallelized, e.g., using parMap.
Map Reduce “Client” Functions: Summing a List
Let’s assume that sum is the standard list summing and psum is the mapReduce parallel summing.
Can we prove that sum and psum are equivalent?
Proving Code Equivalence: sum and psum
The equivalence proof is an instance of the higher order theorem mRTheorem:
Chunk Definition:
First, let’s define the chunk function that splits a list into chunks of size n.
Question: Define the take and drop functions below that satisfy the following specifications:
Question: Define the chunk function below that splits a list into chunks of size n.
Solution
The functions take, drop, and chunk can be defined as follows:
drop :: Int -> [a] -> [a]
drop 0 x = x
drop i (x:xs) = drop (i-1) xs
take 0 _ = []
take i (x:xs) = x : take (i-1) xs
{-@ chunk :: Int -> x:[a] -> [[a]] / [len x] @-}
chunk :: Int -> [a] -> [[a]]
chunk i x
| i <= 0 || length x <= i = [x]
| otherwise = take i x : chunk i (drop i x)Higher Order Theorem: mRTheorem
The higher order theorem mRTheorem states that:
If
fis right identity andopis distributive, thenmapReduceis equivalent to sequential.
Question: What is the proof of mRTheorem?
Solution
The function mRTheorem can be defined as follows:
mRTheorem n f op rightId distrib is
| n <= 0 || length is <= n
= mapReduce n f op is
=== reduce op (f []) (map f (chunk n is))
=== reduce op (f []) [f is]
? rightId is
=== f is
*** QED
mRTheorem n f op rightId distrib is
= mapReduce n f op is
=== reduce op (f []) (map f (chunk n is))
=== reduce op (f []) (map f (take n is : chunk n (drop n is)))
=== reduce op (f []) (f (take n is) : map f (chunk n (drop n is)))
=== op (f (take n is)) (reduce op (f []) (map f (chunk n (drop n is))))
? mRTheorem n f op rightId distrib (drop n is)
=== op (f (take n is)) (f (drop n is))
? distrib (take n is) (drop n is)
=== f (take n is ++ drop n is)
? takeDrop n is
=== f is
*** QED
takeDrop :: Int -> [a] -> Proof
{-@ takeDrop :: i:Nat -> xs:{[a] | i <= len xs }
-> {take i xs ++ drop i xs == xs} @-}
takeDrop 0 xs = ()
takeDrop n (_:xs) = takeDrop (n-1) xsLemmata for mRTheorem on plus
Question: What is the proof of plusRightId?
Solution
The function plusRightId can be defined as follows:
plusRightId [] = ()
plusRightId (x:xs) = plusRightId xs Question: What is the proof of sumDistr?
Solution
The function sumDistr can be defined as follows:
sumDistr [] ys = ()
sumDistr (x:xs) ys = sumDistr xs ys Summary
We saw a case study in which map reduce is used to parallelize the sum of a list. Using Liquid Haskell, we can prove that the parallel sum is equivalent to the sequential sum.
Appendix: List Manipulation Functions
We define the list manipulation functions++ and length below.